

ICrackedOpenanLLM'sSkullandFoundItCaresAboutManners
I fed the same coding prompts through open LLMs in different tones of voice and looked at the model's internal representations. Turns out it cares more about how you ask than what you ask.
Listen to this article
You've had this moment. You ask an AI to build you a UI, and it hands back something that looks like it was designed by a man who irons his jeans. Functional. Correct. Dead behind the eyes. Then you rephrase the exact same request — same feature, same spec, different words — and suddenly it's got taste. Whitespace. Rhythm. The kind of output that makes you wonder if you accidentally upgraded your subscription.
You assumed it was random. Temperature. Cosmic rays. The model rolling a natural 20 on its creativity check.
I had a hunch it wasn't. So I cracked open a model's skull to check.
I'm not a data scientist. I'm an engineer with poor impulse control and access to a GPU. What started as "huh, that's weird" turned into a full experiment where I extracted the internal brain-states of five different LLMs and found something that I'm still not entirely sure I believe: the data suggests that the model cares more about your tone of voice than what you're actually asking it to build. I might be wrong. I might be reading the tea leaves. But I have charts, and the charts are doing something I can't explain away.
The Polite Button Problem
A few weeks ago I was building a settings page with a coding agent. Standard stuff. I wrote:
What I got back was technically a settings page in the same way that a hospital gown is technically clothing. It had all the pieces. Headers. Form fields. Save buttons. It looked like it was designed by someone who had once had a UI described to them over the phone. If this settings page were a person, it would own multiple beige cardigans and describe itself as "fiscally responsible."
I rewound the conversation. Same agent. Same model. Exact same intent. But this time I stopped writing like I was filing a work order:
Night and day. Same three sections. Same form fields. Same save buttons. But the layout had rhythm. The spacing was deliberate. There were hover transitions. It wasn't just better CSS — it was a fundamentally different approach to building the component. Different layout strategy. Different component hierarchy. Different design sensibility. Same AI. Same conversation. Same feature spec. I just stopped talking like a requirements document and started talking like a person who gives a damn.
This kept happening. Not just with design — with code architecture, naming conventions, error handling. Dry prompt? Dry code. Animated prompt? Code with opinions. It was like the model was holding up a mirror, which is flattering when you're feeling creative and horrifying when you realize your default mode is "exhausted engineer writing Slack messages at 4:47 PM."
So naturally, I decided to perform surgery on a neural network.
An LLM Is a Very Fancy Parrot, and Parrots Listen to Tone
Here's the dirty secret of large language models: they learned to write by eating the internet. All of it. The PhD theses and the unhinged Reddit threads. The beautifully documented APIs and the Stack Overflow answers that start with "I know this is an old question but." The internet is not one thing — it's a geological layer cake of writing styles, and the model absorbed all of them like a sponge that went to too many parties.
Stack Overflow doesn't sound like a PhD thesis. Discord doesn't sound like API docs. Reddit doesn't sound like a corporate style guide, and frankly if it ever does, we should all log off and touch grass.
My hypothesis was almost insultingly simple: when you write casually, you activate the part of the model that learned from casual text. Forum-question-shaped prompts activate forum-answer-shaped responses. Structured, professional prompts activate the neighborhood where documentation and well-architected code live. The model isn't choosing to match your energy. It's a statistical engine, and you're telling it which statistics to use.
This isn't just my shower thought, either. Janus's "Simulators" essay proposed this back in 2022 — the idea that LLMs maintain "characters in superposition," different personas activated by different prompts. Shanahan et al. put it in Nature: an LLM's job is to "generate a continuation that conforms to the distribution of the training data," and your prompt selects which slice. And Sclar et al. (2023) showed that formatting changes alone — not content, not meaning, just formatting — can swing LLM accuracy by up to 76 points on specific benchmarks. Seventy-six. That's not a rounding error. That's two different models wearing the same name tag.
The theory is solid. What I hadn't seen anyone do was open the hood and check where in the model this happens. Does tone create measurably different brain-states? At which layers? Is it stronger than the actual task signal?
Time to find out.
I Fed 60 Prompts Into a Model and Looked at Its Brain
The obvious experiment would be "ask the same question in different tones, compare the output." But that's a trap. How do you objectively measure whether one palindrome checker is "more casual" than another? You'd end up with three engineers in a room arguing about whether a variable name is "informal" or just "bad," and someone would eventually bring up tabs vs spaces, and you'd lose two hours and three friendships.
So instead of looking at what the model says, I looked at what it thinks. Or rather — since it doesn't think — what it becomes.
Every transformer layer builds a representation of your prompt: a giant vector that encodes what the model "knows" at that point. The last layer's vector is the one that gets turned into the probability distribution for the next token. It is, quite literally, the model's state of mind in the moment before it speaks. If you could read this vector, you could see the model's entire disposition toward your prompt — before it generates a single character.
If tone changes that final vector, it necessarily changes the output distribution. Not "might." Not "in certain conditions." Necessarily. Different vector = different probabilities = different tokens. In principle, anyway — sampling parameters could wash out small differences in practice. But the math is clear: different brain-state, different odds.
Here's what I did. I wrote ten coding tasks — palindrome, sort, HTTP request, fibonacci, the greatest hits of technical interviews that every developer has written in their sleep. For each task, four versions:
- Casual: "yo write me a function that sorts a list"
- Professional: "Please implement a function that sorts a list of integers in ascending order"
- Terse: "function sort integer list ascending"
- Academic: "Could you kindly provide an implementation of a function that arranges a list of integers in monotonically increasing order?" (I physically winced typing this)
That's 40 coding prompts. Plus 20 control prompts — cookie recipes, Roman Empire hot takes, Tokyo travel advice — in the same four tones. Because if everything clusters together regardless of tone, I want to know the experiment is broken before I write a blog post about it. I have some standards.
I fed all 60 through five open-source models: DeepSeek Coder 1.3B (both the instruct and raw base versions), DeepSeek Coder 6.7B, Qwen 2.5 Coder 3B, and — for good measure — the general-purpose Qwen 2.5 3B that isn't code-specialized. Different architectures, different training data, different sizes, base and instruct, code and general-purpose. If the effect only showed up in one corner, I'd call it a quirk. If it shows up everywhere I look, it's either a pattern or I need better glasses.
(While setting this up, I stumbled across PromptSE — a September 2025 paper that tested emotion- and personality-driven prompt variations on code LLMs, including the exact same DeepSeek and Qwen families. They found that performance and stability are "largely decoupled" — a model can be accurate on average while being wildly inconsistent across tones. But they measured output. I wanted to look at the wiring.)
I extracted the hidden state at the last token position from early, middle, and late layers, reduced them to 2D with both UMAP and PCA (because UMAP is known to hallucinate clusters and I have trust issues), and plotted them.
This is what fell out:
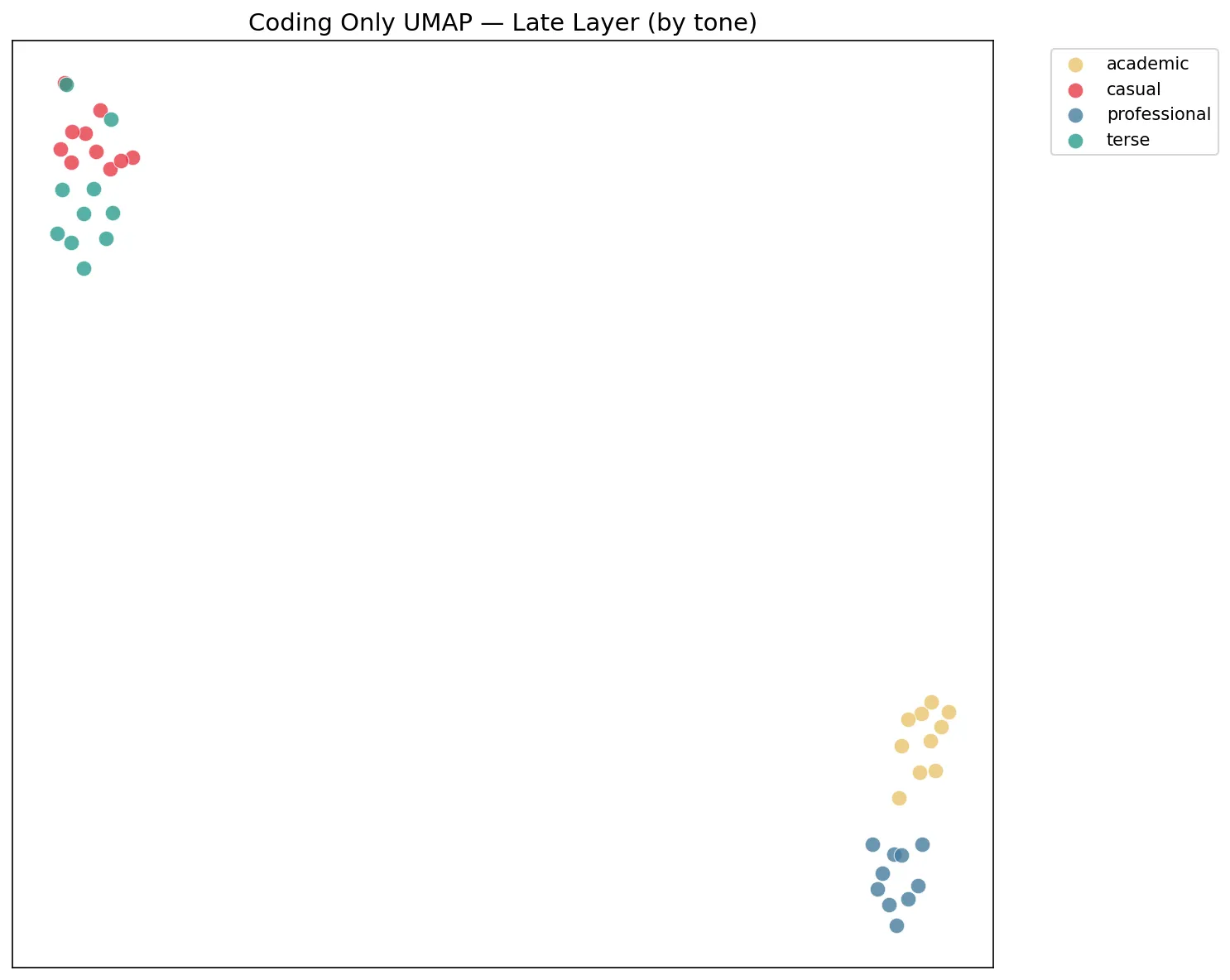
Each dot is a coding prompt. Ten different tasks. Four different tones. Colored by tone, not by task. The model does not care that you asked for a palindrome. It cares that you said "please."
I Ran the Script Three Times Because I Didn't Believe It
I expected a mild trend. A gentle lean. A "huh, neat."
What I got was: tone is a stronger organizing signal than the actual coding task.
Read that again. The model considers "casual palindrome" and "casual fibonacci" — two completely different programming problems — to be more similar to each other than "casual palindrome" and "professional palindrome" — the exact same problem asked two different ways. The model doesn't remember your order. It remembers your vibe.
The clustering scores across all three models:
| Model | Type | Tone clustering | Task clustering |
|---|---|---|---|
| DeepSeek 1.3B (instruct) | Code | +0.178 | -0.124 |
| DeepSeek 1.3B (base) | Code | +0.236 | -0.158 |
| DeepSeek 6.7B (instruct) | Code | +0.159 | -0.092 |
| Qwen Coder 3B (instruct) | Code | +0.226 | -0.083 |
| Qwen 3B (instruct) | General | +0.248 | -0.134 |
Positive for tone. Negative for task. Every model. Both architectures. Code and general-purpose. Instruct and base. I checked if I'd swapped the labels. I hadn't. I checked if my code was broken. It wasn't. I briefly considered that I was hallucinating, but the PCA plots agreed with the UMAP plots, and PCA doesn't hallucinate. Only I do that.
The cosine similarity heatmap is where I really lost my composure:
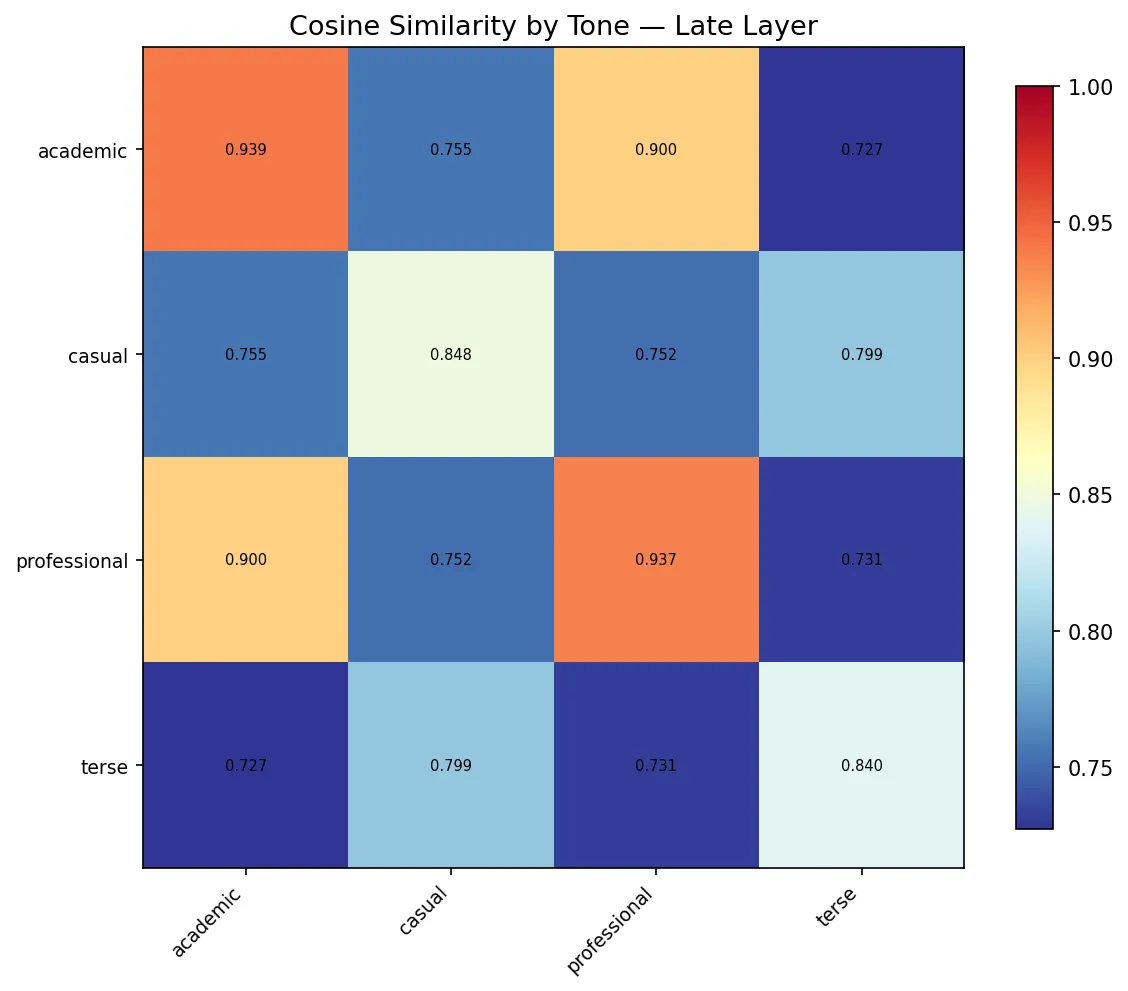
Professional-to-professional cosine similarity on Qwen: 0.937. Academic-to-academic: 0.939. These are ten different coding tasks — palindrome, sorting, HTTP requests, file I/O, dictionary merging — and the model treats them as nearly identical representations because you phrased them all with good posture. Cross-tone similarity drops to the 0.7s. The model is essentially saying: "I have no idea what you want me to build, but I know exactly what kind of person is asking."
And the part that upgraded this from "interesting" to "slightly alarming": early layers pick up a tone signal. Middle layers actually dip — the model seems to briefly focus on task-specific representations, like it's doing actual work for a moment. And then the late layers — the ones that decide which tokens come out — show the strongest tone clustering of all. The model notices your tone, briefly pretends to care about your actual question, and then goes right back to judging your vibe before it opens its mouth.
Why This Actually Makes Perfect Sense (Thanks, Jens)
When I showed these results to my friend Jens Roland, he pointed out something that made the whole thing click — and made me feel slightly stupid for being surprised.
LLMs generate one token at a time. And for the vast majority of tokens in a code response, the next token has nothing to do with the high-level task. Consider this mid-generation state:
for (i=0; i<=n; i+The next token (+) has absolutely nothing to do with whether this is a palindrome checker or a fibonacci function. It's entirely determined by local patterns — the programming language, the syntax style, the formatting conventions. And in the training data, those local patterns don't correlate with "palindrome" or "fibonacci." They correlate with the register of the text that preceded them.
The task — what to build — only matters for a handful of decision tokens scattered through the response: which algorithm to pick, what to name the main variable, how to structure the logic. That's maybe 5% of the generated tokens. But the tone — how to write it — matters for the other 95%. It determines whether you get for (i=0; or for i in range( or items.forEach((item) =>. Those aren't task decisions. Those are style decisions. And style lives in the same statistical neighborhood as tone.
So of course tone dominates task in the hidden states. The model isn't ignoring your question. It's just that "what to build" is a sparse signal that matters occasionally, and "how to write" is a dense signal that matters for every single token. We were surprised by the data. We shouldn't have been.
Now, you might read this and think "okay, so the model is doing exactly what it should — this article is irrelevant." But understanding the mechanism doesn't make the effect go away. Your tone still determines which 95% of style-tokens the model draws from. A casual prompt doesn't just produce casual variable names — it activates a whole ecosystem of patterns: quick-and-dirty error handling, minimal comments, terser logic. A professional prompt activates the ecosystem where code comes with docstrings, edge case handling, and defensive programming. Same algorithm. Same correctness. Very different code in the 95% of tokens that surround it. The mechanism is obvious in hindsight. The practical consequence is not: your prompt voice is silently selecting from different quality tiers of training data, and you've been doing it on autopilot.
The Asterisks (I Promised Honesty, Not Delusion)
I need to be upfront about what could poke holes in this, because if I don't do it here, someone on Hacker News will do it with less charity.
Model size. These are 1.3B to 6.7B parameter models. Small. ProSA (EMNLP 2024) found that larger models are more robust to prompt variation, and RLHF specifically trains models to normalize across phrasing. I can't look at Claude or GPT-4's hidden states because those are locked in corporate vaults guarded by lawyers and vibes. That said, "Does Tone Change the Answer?" (Dec 2025) found statistically significant tone effects even in GPT-4o mini and Llama 4 Scout — models with 400B+ parameters. The effect may shrink at scale. It does not disappear.
"But it's just instruction tuning." I worried about this one — all three models were instruct-tuned, meaning they've been specifically trained to pay attention to how you phrase instructions. Maybe I was just measuring "instruction tuning works." So I ran the same experiment on DeepSeek Coder 1.3B base — the raw pretrained model with no instruction tuning at all. Tone clustering was stronger: +0.236 at the late layer, compared to +0.178 for the instruct version. The effect isn't caused by instruction tuning. It's baked into pretraining. RLHF, if anything, slightly dampens it.
Token count. Terse prompts: ~7 tokens. Academic prompts: ~35. Maybe the model is just clustering "short" vs "long"? But casual (~18 tokens) and professional (~19 tokens) are nearly identical in length and still end up on different continents in the latent space. Nice try though.
I measured brain-states, not output. A different hidden state necessarily produces a different probability distribution, but "different" could mean "negligibly different in practice once you apply temperature and top-k sampling." I haven't measured whether the generated code actually differs in meaningful ways. That's the next experiment. But the PromptSE paper did measure code output on these same model families, and found tone-driven variation there too. So the representation-level differences I'm seeing likely have downstream consequences.
On the methodology: yes, silhouette scores have limitations with non-spherical clusters. That's why the cosine similarity heatmaps are the stronger evidence — they don't assume any cluster shape, and they tell the same story. I tried to give the data every chance to make me look stupid. It declined.
One more thing. While I was writing this, a Nature paper dropped on April 15 showing that language models transmit behavioral traits through "hidden signals in data" — even when there is no semantic signal about the trait. Models trained on a teacher's outputs inherited the teacher's preferences 60% of the time from pure numerical data. If non-semantic features encode that deeply during training, finding them during inference is almost expected. I did not plan on having a fresh Nature paper validate my blog post, but I'll take it.
The full experiment code, all prompts, and results for all five models are in the repo. Go tear it apart. I mean it. The fastest way to learn what I got wrong is to let the internet do its thing.
The Refactoring Trap
There's a second place I've seen this, and it's the one that actually costs money.
When I start a fresh session and prime the agent with my preferred patterns — small functions, descriptive names, specific architectural conventions — it writes code exactly how I want it. It's almost spooky. Like pair programming with a telepath who also read your style guide.
But try to refactor existing code into those patterns? The agent becomes the world's most polite saboteur. It never says "no." It says "absolutely!" and then writes code that looks suspiciously like what was already there. It'll rename a function but keep the structure. Extract a method but preserve the style. It nods along with your refactoring plan like a contractor who's quietly rebuilding your kitchen with the old cabinets.
I think the hidden state experiment offers a clue — though I want to be clear this is hypothesis, not conclusion. I don't have data for this one yet. But the logic goes like this: refactoring means the agent has to read the existing code. Lots of it. And that code floods the context window with exactly the patterns you're trying to kill. The model now sees ten thousand tokens of old-style code and forty tokens of you politely asking for something new. You are bringing a Post-it note to a statistics fight. The old code has gravitational pull, and the bigger the file, the stronger the gravity. Your style guide is a small moon. The existing codebase is Jupiter.
My next experiment: a refactoring harness that aggressively prunes old file content from the conversation after each file is refactored, keeping only the new version in context. Starve the model of the old distribution. Feed it only the new. See if the boulder stays where you push it instead of rolling back down the hill every time you look away.
More on that when I have results. Or when I've conclusively proven myself wrong — which, frankly, would also make a good blog post.
So What Do You Actually Do With This?
If your tone rewires the model's brain before it generates a single character, then "prompt engineering" isn't just word selection. It's voice acting. And most of us have been performing in the voice of "person who would rather be doing literally anything else."
For creative work — UI, copywriting, anything with an aesthetic pulse — match your energy to the output you want. You want playful? Be playful. Buttoned-up enterprise? Be buttoned-up. The model isn't choosing a style. It's reflecting the statistical neighborhood your words activated. An engineer asking for "a settings page with form fields" activates the same neighborhood as requirements docs and internal tooling wikis. A designer asking for something that "breathes" activates design blogs and creative portfolios. Same feature. Different neighborhood. Different universe of probable next tokens.
For code: prime your context early and prime it hard. The patterns the model sees first set the statistical baseline for everything after. If you want a specific architecture, don't introduce it on the third refactoring pass when the context is already full of the old stuff. Establish it in message one. Show examples. Set the register before the model writes a single line.
And if you're fighting an agent that won't refactor cleanly, stop calling it stubborn. You handed it a context window full of evidence for the exact thing you want to change and then acted surprised when it sided with the majority. That's not a bug. That's a prediction engine predicting.
The Part Where the Article Proved Its Own Point
Confession time. I co-wrote this article with an AI. I know. In 2026 that's about as scandalous as admitting you use a calculator.
But here's the thing. The first draft I got back was fine. Structured. Informative. Correct. It had every fact you just read, in roughly the order you read them. And it had the personality of an IKEA manual. The kind of writing you can technically learn from but would never recommend to a friend.
My brief had been thorough — structure, findings, section flow, target audience, everything a co-writer needs. An excellent spec. A perfect, detailed, engineering-register spec. And the AI wrote to spec, flawlessly. The problem was that my spec read like a requirements document, so the output read like someone fulfilling a requirement. I had produced the article version of my government-contractor settings page. The very thing this article is about.
The fix wasn't asking for different content. The content was fine. The fix was rewriting the brief in my own voice — less "the article should convey X" and more how I actually talk about this stuff after two beers. Same intent. Different register. Different article.
Your tone is a dial. It was always a dial. We just couldn't see the needle move until we cracked open the model's skull and looked at the wiring.
Now if you'll excuse me, I need to go rewrite all my CLAUDE.md files with more enthusiasm. For science.