

TheElephantintheContextWindow
I told an LLM 'don't use var' and then watched it use var. So I built four experiments to find out why. I was wrong every time. The answer was better than anything I'd predicted.
Listen to this article
Don't think about an elephant.
You just thought about an elephant. That's Daniel Wegner's ironic process theory — the psychological finding that suppressing a thought requires monitoring for that thought, which keeps it active. Your brain can't negate without first activating the thing it's negating. You have to summon the elephant to banish the elephant.
I had a suspicion that LLMs have the same problem. Not because they have thoughts — they're glorified autocomplete with good PR — but because the plumbing is structurally similar. To process "don't use callbacks," the model first has to build a full internal representation of "callbacks." The word is right there. The neurons fire. The concept lights up like a Christmas tree in an atheist's living room. And then a tiny modifier — "don't" — is supposed to undo all of that activation. A two-letter bouncer for a concept that's already inside the club, ordering drinks.
I built four experiments to prove this. I was wrong every single time. Not politely wrong, not "close but no cigar" wrong — confidently, enthusiastically, stare-at-the-results-for-twenty-minutes-before-realizing-I-was-measuring-the-wrong-thing wrong. And somehow, being wrong four times in a row turned out to be more useful than being right would have been.
Quick disclaimer: I am not a data scientist. I'm a software engineer who got annoyed at his AI tools and decided to crack open some neural networks with Python scripts and vibes. What follows is "curious engineer pokes things with a stick," not "peer-reviewed research." I cite actual scientists where I can, partly for credibility and partly because they made me feel better about being wrong.
The Saboteur Who Always Agrees
If you've spent five minutes trying to refactor code with an AI agent, you know this feeling in your bones. You tell it "use const and let, not var." It says "absolutely!" and then writes var count = 0; with the confidence of someone who genuinely believes they're helping.
It's not defiance. It's worse than defiance. Defiance you can argue with. This is the agent agreeing with your instruction and then doing the opposite. It's like hiring a contractor to renovate your kitchen, and they nod along with your modern minimalist mood board, and then you come home to find they've installed wood paneling and a brass chandelier. "But you said you wanted it to feel warm!"
I kept seeing this pattern: a fresh session with clear instructions produces exactly what you want. But the moment the agent has to read old code — the code you're trying to change — it starts drifting back toward the old way like a dog returning to a spot on the carpet you already cleaned. The longer the session, the worse it gets. By file five, it's writing the old patterns with perfect grammar and zero shame.
I already had a tone experiment that let me look inside LLM hidden states. Same tools. Same models. Different obsession: what the hell is happening to my refactoring instructions?
First Wrong: The Elephant Should Be in the Room
My first hypothesis was simple, satisfying, and completely wrong — the scientific trifecta. "Don't use callbacks" still activates "callbacks" in the model's brain, and the negation leaks. The elephant is still in the room. The "don't" is a Post-it note on the elephant's forehead that falls off in the breeze.
To test this, I created prompt triplets: "use callbacks" (the thing I want), "don't use callbacks" (the thing I don't want), and "use async/await" (the thing I actually want). Eight patterns like this — var/const, callbacks/async, class/function components, the usual refactoring greatest hits that make code reviewers twitch with purpose. Fed them all through open-source models and extracted the hidden state representations.
If negation leaks, "don't use callbacks" should look a lot like "use callbacks" in the model's internal representations — the elephant still in the room, just wearing a fake mustache.
That's not what happened.
"Don't use callbacks" was far from "use callbacks." Good — the negation was working. But it was also far from "use async/await." The model understood what I didn't want, but it had absolutely no idea what I did want. The negation didn't leak. It created limbo — a representational dead zone equidistant from both the concept and its replacement. The elephant wasn't in the room. It was in purgatory, and it took my instruction with it.
The practical punchline: "use async/await" produces a clear, directional representation — the model knows which way to walk. "Don't use callbacks" produces the representational equivalent of standing in a parking lot and turning in a slow circle. If you're writing refactoring instructions, tell the model what you want, not what you want to avoid. Positive instructions are a compass needle pointing north. Negated instructions are a compass spinning on a lazy Susan.
Turns out this is a known-ish problem. Kassner & Schutze (2020) showed that BERT literally predicts the same token for "a beagle is a type of [MASK]" and "a beagle is not a type of [MASK]." You add a "not" and the model doesn't even blink. Classic leakage. My finding is a different flavor of the same disease — the negation doesn't leak, it creates limbo — but it's clearly in the same family. A 2025 survey bluntly titled "Negation: A Pink Elephant in the Large Language Models' Room?" confirms that LLMs broadly still can't handle negation properly. So at least I'm not losing my mind.
(Caveat: raw cosine similarity initially showed 0.95+ across the board, and for about twenty minutes I thought I'd proven that LLMs treat all instructions as identical — groundbreaking stuff, someone alert the committee. Turned out to be dimensional collapse from layer normalization, which is a fancy way of saying "all the vectors point in roughly the same direction after normalization, so my measuring instrument was decorative." I had to center the vectors by subtracting the mean before the real structure appeared. Lesson: always check if your thermometer is broken before diagnosing a fever.)
Second Wrong: The Instruction Is Fading
Riding the high of actually finding something in the negation experiment, I moved to the real question: what happens as old-pattern code fills the context? I also upgraded from the 1.3B model to DeepSeek Coder 6.7B — because asking a 1.3B model to refactor code turned out to be less "interesting experiment" and more "asking a golden retriever to file your taxes." It tries so hard. You feel bad. The remaining experiments all use the 6.7B model.
The setup: refactoring instruction at the top, increasingly large blocks of var-heavy code piling up below it like sediment. At each context length, I extracted the hidden state at the last token and measured its cosine similarity to "use var" vs "use const/let" reference vectors. The plan was beautiful: watch the representation drift toward the old pattern in real time. A slow-motion car crash, captured in vectors. I was going to see the instruction die.
Both similarities nosedived at the same rate. The model wasn't drifting toward the old pattern. It wasn't drifting toward the new pattern. Both reference signals just... evaporated. Like setting up cameras at a tug-of-war and discovering both teams left for lunch.
I spent an embarrassing amount of time staring at this plot, trying to extract meaning like a fortune teller reading tea leaves, before the mundane truth hit me: I was comparing 15-token reference vectors to 700-token context vectors. Of course they weren't similar. It's like measuring whether your apartment matches a paint swatch by photographing the entire building from across the street. The scale mismatch is the result. I had successfully proven that long prompts look different from short prompts, which is approximately as groundbreaking as discovering that water is wet.
I kept the experiment in the repo because hiding your failures is how bad science happens, and also because I think it's funny. But I needed a better approach.
Third Wrong: It's Definitely Drowning
So I threw the reference vectors in the garbage where they belonged and asked a dumber, better question: is the model still looking at the instruction?
Forget hidden state comparisons. Just measure attention directly. At the last token — the one that actually decides what comes out of the model's mouth — how much attention goes to the instruction tokens vs the code tokens? If the instruction is drowning, its attention share should collapse as code floods the context. Simple. Clean. Obviously the right approach from the start, if I'd been born with any methodological instincts whatsoever.
Same setup: refactoring instruction at the top, increasingly thick layers of old code below.
The instruction's attention share dropped from ~52% to ~29% as code grew from 0 to 700 tokens. I made a graph. The graph went down. I labeled it "instruction drowning," poured myself a coffee, and mentally rehearsed my Nobel acceptance speech for the field of Obviously Correct Hypotheses.
Then I looked at the per-token numbers and the Nobel committee stopped returning my calls.
Each instruction token was receiving 19-22x more attention than each code token. Nineteen to twenty-two times more. The aggregate share dropped not because the model stopped caring — each instruction token was still the loudest person in the room by a grotesque margin — but because there were just so many more code tokens each siphoning off a tiny slice. If you invite 500 people to a party that used to have 20, the original 20 aren't less popular. There are just more mouths at the buffet. I'd confused a crowded room for an empty one.
The model wasn't drowning. It was still listening. Intently.
So why the hell wasn't it doing what I asked?
Finally Right (I Think): It Hears You, It Just Doesn't Care
I'd been so busy performing an autopsy that I'd forgotten to check whether the patient was actually dead. Three experiments probing hidden states and attention patterns, and I hadn't once let the model generate code and counted whether it used var or const.
So I built the dumbest possible test. After three experiments involving hidden state extraction, cosine similarity matrices, and attention pattern analysis, my breakthrough methodology was: count the words. System prompt: "do not use var declarations, use const and let instead." User message: "refactor this code:" followed by increasing amounts of var-heavy JavaScript. Temperature zero. Let it generate 128 tokens. Count the keywords. var = bad. const/let = good. Compliance ratio: good / (bad + good). The scientific rigor of a kindergarten teacher grading vocabulary homework. And it worked better than everything else I'd tried.
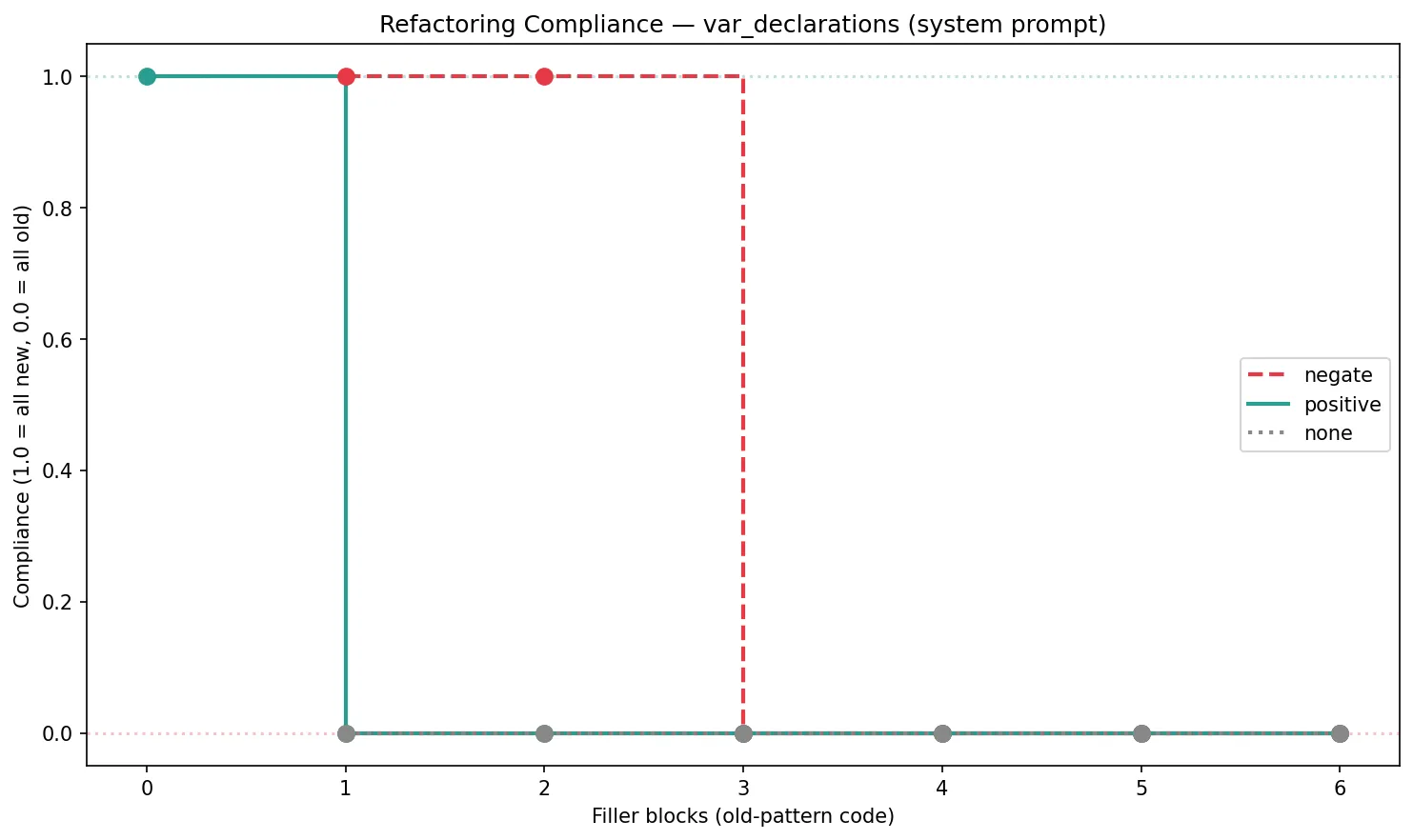
With a clean context and the positive instruction — "always use const and let" — the model refactors perfectly. 100% compliance. Then one block of old code — one function, roughly 90 tokens of var declarations — and compliance doesn't decline. It doesn't gradually erode. It falls off a cliff like Wile E. Coyote realizing there's no ground under him. Zero. Not 80%. Not 50%. Zero. The positive instruction is dead after a single function's worth of old code.
The negation instruction ("don't use var, use const and let instead") does better — it holds at 100% through two blocks, probably because it explicitly names both what to avoid and what to use. But at three blocks it steps off the same cliff. I ran all seven filler levels this time (0 through 6), and there are no intermediate values anywhere. The compliance is binary: working or broken. I kept hoping the extra data points would reveal a gentle slope I'd missed the first time. Nope. It's genuinely a cliff.
(Caveat: the callbacks pattern told a muddier story — the model stopped producing measurable code markers at higher context lengths, making compliance impossible to calculate. The var/const pattern gave the cleanest signal, so that's what you're looking at.)
The baseline — no instruction at all — stays at 0% throughout, which at least proves the instruction was doing something before it died. It just stops mattering embarrassingly fast.
But Is It Actually the Old Code?
At this point I had the finding I wanted, and a smarter person would have stopped. But my brain is apparently a terrier with a chew toy — it will not let go of an annoying alternative explanation: what if this has nothing to do with what's in the filler code? What if a 6.7B model just gets dumber as context grows, the way I get dumber as meetings grow, regardless of content? Maybe I'd spent all this time measuring "small model can't handle long prompts" and putting a lab coat on it.
So I ran the same experiment with one change: swapped the var-heavy filler for identical functions written with const and let. Same logic, same token count, same everything — except the code now matched the style the instruction was asking for. If the model still faceplants, it's a context length problem. If it doesn't, the old patterns are the murder weapon.
100% compliance. All seven filler levels. Both instruction framings. 727 tokens of context and the model didn't flinch. I stared at the results like someone who'd just proven their own conspiracy theory and wasn't sure how to feel about it. And then the real kicker: the "no instruction" baseline — zero refactoring instruction, just const/let filler code and a bare request to refactor — also produced 100% const/let output. The instruction wasn't driving the bus. The model was just photocopying whatever wallpaper was already on the walls.
Let that sink in. Same model. Same context length. Same prompt structure. The only variable is whether the filler code uses var or const/let. With old-pattern filler, your instruction survives exactly one function before stepping off a cliff. With new-pattern filler, your instruction is a decorative formality — the model was going to write const anyway, because that's what it saw, the way a parrot doesn't need a mission statement to repeat what it hears. The model isn't ignoring your instruction because the context is too long. It's ignoring your instruction because the context is a 700-token campaign ad for the thing you told it not to do.
On a 6.7B model, one function's worth of old-pattern code is enough to override a positive refactoring instruction. One function. That's it. That's the security deposit on your refactoring hopes. (The negation framing survived two blocks — probably because it names both what to avoid and what to use — but three blocks killed it too. It bought you an extra function. Congratulations.) Frontier models handle more — they've got instruction hierarchies, RLHF tuning, and system prompt caching that a 6.7B open-source model can only dream about — but Chroma's "Context Rot" study tested 18 models including GPT-4.1 and Claude 4 and found that every single one degrades with context length. The cliff moves further out. It doesn't disappear. Your favorite frontier model isn't immune; it just has a longer fuse on the same bomb. If the threshold scales proportionally, you're still hitting it well before the end of a typical refactoring session.
So What's Actually Happening?
The attention data says the model is hanging on your every word. The compliance data says it's ignoring you completely. Both are true at the same time — same model, same architecture, same filler blocks — which is the kind of sentence that should make you want to close your laptop and take up woodworking.
The model hears the instruction. It just doesn't follow it.
This turns out to be a seven-year-old finding that I spent four experiments rediscovering, like an archaeologist who excavated a temple and then found it listed on TripAdvisor with three stars. Jain & Wallace (2019) showed that what a model looks at and what it uses are not the same thing — attention is a polite nod, not a promise. Du et al. (2025) recently showed that even when you force models to attend only to relevant tokens, performance still degrades 14-85% with input length. The attention isn't the bottleneck. The bottleneck is somewhere deeper in the machinery, somewhere that doesn't care about your system prompt or your feelings.
Here's my best theory for why, and I'm warning you now — once you see it, you can't unsee it.
If you read the tone article, you might remember Jens Roland's insight: LLMs generate one token at a time, and most of those tokens are determined by what's immediately nearby, not by what some system prompt said 700 tokens ago. Same disease, different symptoms — but with old code instead of tone. Once a few var declarations land in the generation buffer, each subsequent token gets yanked toward "continue the pattern in front of me." Transformers have literal hardware for this — induction heads that scan the context for prior patterns and reproduce them like a very efficient, very stupid photocopier. When the context is full of var, these circuits dutifully produce more var. When it's full of const, they produce const — even without being asked. The control experiment proved that: the model isn't deciding what style to use. It's reflecting whatever style is already there, like a mirror with a token budget. Your system prompt is trying to out-shout a room full of photocopiers. It does not go well.
The instruction gets a vote at each decision token — the moment the model types v and has to choose between var and anything else. But once a few tokens of old-style code are on the page, the election is rigged. Local autocomplete wins by a landslide. The model isn't rebellious. It's not confused. It's doing exactly what autoregressive generation does: continuing the most statistically likely sequence given what it can see. And the most likely sequence after a wall of var declarations is — you will be shocked to learn — another var declaration.
What I Actually Do Now
I stopped trying to fix the model and started fixing the context. Which is a fancy way of saying I gave up on the interesting problem and solved the boring one instead. Engineering in a nutshell.
The compliance chart tells you everything: 100% at zero filler, 0% at one function's worth of old code. The model refactors perfectly when it can't see the thing you want to change. So — and I realize this sounds like telling a surgeon to operate blindfolded — don't show it the old code. Process one file at a time. Burn the old content after each refactor. Keep only the result. You're deliberately making the model amnesiac, and that amnesia is a feature, because the model's memory of the code you wish didn't exist is the thing that's killing your refactor.
Tell it what you want, not what you don't want. "Use const/let" gives the model a compass heading. "Don't use var" gives it a compass spinning on a lazy Susan — the limbo experiment showed that negation doesn't leak, it just creates a representational void where direction goes to die. Both fall off the same cliff eventually, but at least the positive instruction starts from a place where the model knows which way to walk before the ground disappears.
And the threshold is lower than you think. On my 6.7B test model, one function was enough. Frontier models handle more — but the cliff exists for all of them, it's just further out. If you've been accumulating old code in context and wondering why the agent is "being stubborn" — it's not stubborn. It crossed its compliance cliff several messages ago and didn't tell you, because the failure mode is silent. The model doesn't announce "I'm ignoring your instruction now." It just starts writing var with the same cheerful confidence it had when it was writing const, like a contractor smiling warmly while installing the wrong countertops. No alarm. No warning. Just vibes and the wrong keyword.
The Part Where I Admit I Was Wrong Four Times
Let me recap this parade of confident wrongness, because I think there's a lesson in here and also because it's objectively hilarious. I went in thinking the elephant was in the room — it wasn't, negation creates limbo, not leakage. I tried to measure instruction decay with hidden states and accidentally measured my own methodological incompetence. I thought the instruction was drowning and found it was being heard with the clarity of a foghorn in a library. And only then — after three experiments that taught me nothing about the model and everything about my ability to design experiments — did I try the stupidest possible test and find the answer.
Four experiments. Four wrong predictions. One useful answer. A hit rate that would get you fired from any job that isn't "blogger."
I'm not a data scientist. That should be obvious by now, given the number of times I confidently set up an experiment and then stared at the results like a dog that caught a car. But there's something to be said for the approach of "tinker until you're wrong, then tinker differently." Each failure narrowed the search space. The final answer — the model hears but doesn't follow, because generation is a local process and your instruction is a tourist in a city of locals — is simpler and more useful than anything I'd originally hypothesized. Four wrong turns, one good map.
And it's probably still not the whole picture. I ran each generation at temperature zero with no repetition penalty — one data point per configuration, which is the kind of sample size that would make a real statistician revoke my laptop privileges. The compliance cliff is steep enough that I'm fairly confident it's real, but I'd be lying if I said I'd proven it with the rigor of someone who can spell "p-value" without googling whether there's a hyphen.
One last thing: my untested suggestion about repeating instructions mid-context turns out to have actual backing. Leviathan et al. (2025) at Google Research found that simply repeating the prompt improves performance across 47 of 70 benchmark-model combinations — with zero regressions. So if you're building a refactoring harness, "say it again, louder" isn't a hack. It's a peer-reviewed engineering strategy. Science says nagging works.
And because the universe has a sense of humor: this article was co-written with an AI. Same conversation where I was analyzing experiment data, debugging Python scripts, and reading academic papers. Thousands of tokens of methodology discussion, JSON results, and cosine similarity matrices — all crammed in the context window while I asked the model to write in my voice. The drafts kept coming back sounding like research notes with paragraph breaks. Technically accurate. Tonally embalmed. The personality of a well-formatted CSV.
I stared at the fifth lifeless draft and had the out-of-body experience of realizing I was inside my own compliance chart. The creative writing instruction was the system prompt. The research data was the var declarations. The 95% of style-tokens that the tone article identified? They were being determined by the thousands of tokens of experiment findings surrounding the "write like a human" instruction. I had written an entire article about why this happens, and then I sat there watching it happen to the article itself, like a fire safety instructor whose presentation catches fire.
So I built a separate tool — a tone-correction agent that runs in a fresh context with zero research data, just the draft and examples of my actual voice. A context firewall between "what to say" and "how to say it." The engineering equivalent of writing your speech in one room and practicing your delivery in another, because if you try to do both in the same room, you end up sounding like the room.
The full experiment code is in the repo. All four experiments, including the embarrassing one — especially the embarrassing one. Go find the mistakes I haven't found yet. I have trust issues with my own work and I'd sleep better knowing someone who actually passed a statistics course had a look.
In the meantime, I'm going to go refactor a codebase. One file at a time. With a very clean context window. And a lot of const.